Job scheduling events
After performing the configuration steps described in the Configuring the Tivoli Enterprise Console adapter, use the events gathered from the HCL Workload Automation log file using the Tivoli Enterprise Console logfile adapter to perform event management and correlation using the Tivoli Enterprise Console in your scheduling environment.
This section describes the events that are generated by using to the information stored in the log file specified in the BmEvents.conf configuration file stored on the system where you installed the Tivoli Enterprise Console logfile adapter.
An important aspect to be considered when configuring the integration with the Tivoli Enterprise Console using event adapters is whether to monitor only the master domain manager or every HCL Workload Automation agent.
If you integrate only the master domain manager, all the events coming from the entire scheduling environment are reported because the log file on a master domain manager logs the information from the entire scheduling network. On the Tivoli Enterprise Console event server and TEC event console all events will therefore look as if they come from the master domain manager, regardless of which HCL Workload Automation agent they originate from. The workstation name, job name, and job stream name are still reported to Tivoli Enterprise Console, but as a part of the message inside the event.
If, instead, you install a Tivoli Enterprise Console logfile adapter on every HCL Workload Automation agent, this results in a duplication of events coming from the master domain manager, and from each agent. Creating and using a Tivoli Enterprise Console that detects these duplicated events, based on job_name, job_cpu, schedule_name, and schedule_cpu, and keeps just the event coming from the log file on the HCL Workload Automation agent, helps you to handle this problem. The same consideration also applies if you decide to integrate the backup master domain manager, if defined, because the log file on a backup master domain manager logs the information from the entire scheduling network. For information on creating new rules for the Tivoli Enterprise Console refer to the IBM Tivoli Enterprise Console Rule Builder's Guide. For information on how to define a backup master domain manager refer to HCL Workload Automation: Planning and Installation Guide.
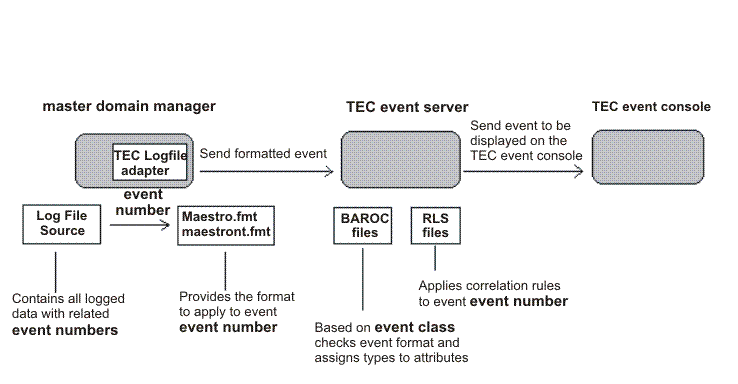
- The information logged during the job scheduling process has an event number for each type of logged activity or problem.
- Each item of information marked with an event number that appears in the EVENT field of the BmEvents.conf file is written into the log file specified in the FILE field of the BmEvents.conf file.
- The Tivoli Enterprise Console logfile adapter reads this information inside the log file, formats it using the structure stored in the FMT file (maestro.fmt for UNIX, maestro_nt.fmt for Windows) and forwards it to the TEC event server, using the TEC gateway defined on the managed node of the Tivoli® environment.
- On the TEC event server, the structure of the formatted information is checked using the information stored in the BAROC files and, if correct, is accepted. Otherwise a parsing failure is prompted.
- Once the event is accepted by the TEC event server, a check on possible predefined correlation rules or automatic responses for that event number is made using the information stored in the RLS files.
- If defined, the correlation rules and/or automatic responses are triggered and the event is sent to the TEC event console to be displayed on the defined Event Console.
For some error conditions on event informing that the alarm condition is ended is also stored in the log file and passed to the TEC event server via the Tivoli Enterprise Console logfile adapter. This kind of event is called a clearing event. It ends on the TEC event console any related problem events.
The following table describes the events and rules provided by HCL Workload Automation.
The text of the message that is assigned by the FMT file to the event is shown in bold. The text message is the one that is sent by the Tivoli Enterprise Console logfile adapter to TEC event server and then to the TEC event console. The percent sign (%s) in the messages indicates a variable. The name of each variable follows the message between brackets.
| Event | Characteristic | Description |
|---|---|---|
| "TWS process %s has been reset on host %s" (program_name, host_name) | Event Class: | TWS_Process_Reset |
| Event Severity: | HARMLESS | |
| Event Description: | HCL Workload Automation daemon process reset. | |
| "TWS process %s is gone on host %s" (program_name, host_name) | Event Class: | TWS_Process_Gone |
| Event Severity: | CRITICAL | |
| Event Description: | HCL Workload Automation process gone. | |
| "TWS process %s has abended on host %s" (program_name, host_name) | Event Class: | TWS_Process_Abend |
| Event Severity: | CRITICAL | |
| Event Description: | HCL Workload Automation process abends. | |
| "Job %s.%s failed, no recovery specified" (schedule_name, job_name) | Event Class: | TWS_Job_Abend |
| Event Severity: | CRITICAL | |
| Automated Action (UNIX only): | Send job stdlist to the TWS_user. | |
| Event Description: | Job failed, no recovery specified. | |
| Correlation Activity: | If this job has abended more than once within a 24 hour time window, send a TWS_Job_Repeated_Failure event. | |
| "Job %s.%s failed, recovery job will be run then schedule %s will be stopped" (schedule_name, job_name, schedule_name) | Event Class: | TWS_Job_Abend |
| Event Severity: | CRITICAL | |
| Automated Action (UNIX only): | Send job stdlist to the TWS_ user. | |
| Event Description: | Job failed, recovery job runs, and schedule stops. | |
| Correlation Activity: | If this job has abended more than once within a 24 hour time window, send a TWS_Job_Repeated_Failure event. | |
| "Job %s.%s failed, this job will be rerun" (schedule_name, job_name) | Event Class: | TWS_Job_Abend |
| Event Severity: | CRITICAL | |
| Automated Action (UNIX only): | Send job stdlist to the TWS_user. | |
| Event Description: | Job failed, the job is rerun. | |
| Correlation Activity: | If this job has abended more than once within a 24 hour time window, send a TWS_Job_Repeated_Failure event. | |
| "Job %s.%s failed, this job will be rerun after the recovery job" (schedule_name, job_name) | Event Class: | TWS_Job_Abend |
| Event Severity: | CRITICAL | |
| Automated Action (UNIX only): | Send job stdlist to the TWS_user. | |
| Event Description: | Job failed, recovery job is run, and the job is run again. | |
| Correlation Activity: | If this job has abended more than once within a 24 hour time window, send a TWS_Job_Repeated_Failure event. | |
| "Job %s.%s failed, continuing with schedule %s" (schedule_name, job_name, schedule_name) | Event Class: | TWS_Job_Abend |
| Event Severity: | CRITICAL | |
| Automated Action (UNIX only): | Send job stdlist to user TWS_user. | |
| Event Description: | Job failed, the schedule proceeds. | |
| Correlation Activity: | If this job has abended more than once within a 24 hour time window, send a TWS_Job_Repeated_Failure event. | |
| "Job %s.%s failed, running recovery job then continuing with schedule %s" (schedule_name, job_name, schedule_name) | Event Class: | TWS_Job_Abend |
| Event Severity: | CRITICAL | |
| Automated Action (UNIX only): | Send job stdlist to the TWS_user. | |
| Event Description: | Job failed, recovery job runs, schedule proceeds. | |
| Correlation Activity: | If this job has abended more than once within a 24 hour time window, send a TWS_Job_Repeated_Failure event. | |
| "Failure while rerunning failed job %s.%s" (schedule_name, job_name) | Event Class: | TWS_Job_Abend |
| Event Severity: | CRITICAL | |
| Automated Action (UNIX only): | Send job stdlist to the TWS_user. | |
| Event Description: | Rerun of abended job abends. | |
| Correlation Activity: | If this job has abended more than once within a 24 hour time window, send a TWS_Job_Repeated_Failure event. | |
| "Failure while recovering job %s.%s" (schedule_name, job_name) | Event Class: | TWS_Job_Abend |
| Event Severity: | CRITICAL | |
| Automated Action (UNIX only): | Send job stdlist to the TWS_user. | |
| Event Description: | Recovery job abends. | |
| Correlation Activity: | If this job has abended more than once within a 24 hour time window, send a TWS_Job_Repeated_Failure event. | |
| "Multiple failures of Job %s#%s in 24 hour period" (schedule_name, job_name) | Event Class: | TWS_Job_Repeated_Failure |
| Event Severity: | CRITICAL | |
| Event Description: | Same job fails more than once in 24 hours. | |
| "Job %s.%s did not start" (schedule_name, job_name) | Event Class: | TWS_Job_Failed |
| Event Severity: | CRITICAL | |
| Event Description: | Job failed to start. | |
| "Job %s.%s has started on CPU %s" (schedule_name, job_name, cpu_name) | Event Class: | TWS_Job_Launched |
| Event Severity: | HARMLESS | |
| Event Description: | Job started. | |
| Correlation Activity: | Clearing Event - Close open job prompt events related to this job. | |
| "Job %s.%s has successfully completed on CPU %s" (schedule_name, job_name, cpu_name) | Event Class: | TWS_Job_Done |
| Event Severity: | HARMLESS | |
| Event Description: | Job completed successfully. | |
| Correlation Activity: | Clearing Event - Close open job started events for this job and auto-acknowledge this event. | |
| "Job %s.%s suspended on CPU %s" (schedule_name, job_name, cpu_name) | Event Class: | TWS_Job_Suspended |
| Event Severity: | WARNING | |
| Event Description: | Job suspended, the until time expired (default option suppress). | |
| "Job %s.%s is late on CPU %s" (scheduler_name, job_cpu) | Event Class: | TWS_Job_Late |
| Event Severity: | WARNING | |
| Event Description: | Job late, the deadline time expired before the job completed. | |
| "Job %s.%s:until (continue) expired on CPU %s", schedule_name, job_name, job_cpu | Event Class: | TWS_Job_Until_Cont |
| Event Severity: | WARNING | |
| Event Description: | Job until time expired (option continue). | |
| "Job %s.%s:until (cancel) expired on CPU %s", schedule_name, job_name, job_cpu | Event Class: | TWS_Job_Until_Canc |
| Event Severity: | WARNING | |
| Event Description: | Job until time expired (option cancel). | |
| (TWS Prompt Message) | Event Class: | TWS_Job_Recovery_Prompt |
| Event Severity: | WARNING | |
| Event Description: | Job recovery prompt issued. | |
| "Schedule %s suspended", (schedule_name) | Event Class: | TWS_Schedule_Susp |
| Event Severity: | WARNING | |
| Event Description: | Schedule suspended, the until time expired (default option suppress). | |
| "Schedule %s is late", (schedule_name) | Event Class: | TWS_Schedule_Late |
| Event Severity: | WARNING | |
| Event Description: | Schedule late, the deadline time expired before the schedule completion. | |
| "Schedule %s until (continue) expired", (schedule_name) | Event Class: | TWS_Schedule_Until_Cont |
| Event Severity: | WARNING | |
| Event Description: | Schedule until time expired (option continue). | |
| "Schedule %s until (cancel) expired", (schedule_name) | Event Class: | TWS_Schedule_Until_Canc |
| Event Severity: | WARNING | |
| Event Description: | Schedule until time expired (option cancel). | |
| "Schedule %s has failed" (schedule_name) | Event Class: | TWS_Schedule_Abend |
| Event Severity: | CRITICAL | |
| Event Description: | Schedule abends. | |
| Correlation Activity: | If event is not acknowledged within 15 minutes, send mail to TWS_user (UNIX only). | |
| "Schedule %s is stuck" (schedule_name) | Event Class: | TWS_Schedule_Stuck |
| Event Severity: | CRITICAL | |
| Event Description: | Schedule stuck. | |
| Correlation Activity: | If event is not acknowledged within 15 minutes, send mail to TWS_user (UNIX only). | |
| "Schedule %s has started" (schedule_name) | Event Class: | TWS_Schedule_Started |
| Event Severity: | HARMLESS | |
| Event Description: | Schedule started. | |
| Correlation Activity: | Clearing Event - Close all related pending schedule, or schedule abend events related to this schedule. | |
| "Schedule %s has completed" (schedule_name) | Event Class: | TWS_Schedule_Done |
| Event Severity: | HARMLESS | |
| Event Description: | Schedule completed successfully. | |
| Correlation Activity: | Clearing Event - Close all related schedule started events and auto-acknowledge this event. | |
| (Global Prompt Message) | Event Class: | TWS_Global_Prompt |
| Event Severity: | WARNING | |
| Event Description: | Global prompt issued. | |
| (Schedule Prompt's Message) | Event Class: | TWS_Schedule_Prompt |
| Event Severity: | WARNING | |
| Event Description: | Schedule prompt issued. | |
| (Job Recovery Prompt's Message) | Event Class: | TWS_Job_Prompt |
| Event Severity: | WARNING | |
| Event Description: | Job recovery prompt issued. | |
| "Comm link from %s to %s unlinked for unknown reason" (hostname, to_cpu) | Event Class: | TWS_Link_Dropped |
| Event Severity: | WARNING | |
| Event Description: | HCL Workload Automation link to CPU dropped for unknown reason. | |
| "Comm link from %s to %s unlinked via unlink command" (hostname, to_cpu) | Event Class: | TWS_Link_Dropped |
| Event Severity: | HARMLESS | |
| Event Description: | HCL Workload Automation link to CPU dropped by unlink command. | |
| "Comm link from %s to %s dropped due to error" (hostname, to_cpu) | Event Class: | TWS_Link_Dropped |
| Event Severity: | CRITICAL | |
| Event Description: | HCL Workload Automation link to CPU dropped due to error. | |
| "Comm link from %s to %s established" (hostname, to_cpu) | Event Class: | TWS_Link_Established |
| Event Severity: | HARMLESS | |
| Event Description: | HCL Workload Automation CPU link to CPU established. | |
| Correlation Activity: | Close related TWS_Link_Dropped or TWS_Link_Failed events and auto-acknowledge this event. | |
| "Comm link from %s to %s down for unknown reason" (hostname, to_cpu) | Event Class: | TWS_Link_Failed |
| Event Severity: | CRITICAL | |
| Event Description: | HCL Workload Automation link to CPU failed for unknown reason. | |
| "Comm link from %s to %s down due to unlink" (hostname, to_cpu) | Event Class: | TWS_Link_Failed |
| Event Severity: | HARMLESS | |
| Event Description: | HCL Workload Automation link to CPU failed due to unlink. | |
| "Comm link from %s to %s down due to error" (hostname, to_cpu) | Event Class: | TWS_Link_Failed |
| Event Severity: | CRITICAL | |
| Event Description: | HCL Workload Automation CPU link to CPU failed due to error. | |
| "Active manager % for domain %" (cpu_name, domain_name) | Event Class: | TWS_Domain_Manager_Switch |
| Event Severity: | HARMLESS | |
| Event Description: | HCL Workload Automation domain manager switch has occurred. | |
| Long duration for Job %s.%s on CPU %s. (schedule_name, job_name, job_cpu) | Event Class: | TWS_Job_Launched |
| Event Severity: | WARNING | |
| Event Description: | If after a time equal to estimated duration, the job is still in exec status, a new message is generated. | |
| Job %s.%s on CPU %s, could miss its deadline. (schedule_name, job_name, job_cpu) | Event Class: | TWS_Job_Ready, TWS_Job_Hold |
| Event Severity: | WARNING | |
| Event Description: | If the job has a deadline and the sum of job estimated start time and estimated duration is greater than the deadline time, a new message is generated. | |
| Start delay of Job %s.%s on CPU %s. (schedule_name, job_name, job_cpu) | Event Class: | TWS_Job_Ready |
| Event Severity: | WARNING | |
| Event Description: | If the job is still in ready status, after n minutes a new message is generated. The default value for n is 10. |
Default criteria that control the correlation of events and the automatic responses can be changed by editing the file maestro_plus.rls (in UNIX environments) or maestront_plus.rls (in Windows environments) file. These RLS files are created during the installation of HCL Workload Automation and compiled with the BAROC file containing the event classes for the HCL Workload Automation events on the TEC event server when the Setup Event Server for TWS task is run. Before modifying either of these two files, make a backup copy of the original file and test the modified copy in your sample test environment.
rule: job_ready_open : (
description: 'Start a timer rule for ready',
event: _event of_class 'TWS_Job_Ready'
where [
status: outside ['CLOSED'],
schedule_name: _schedule_name,
job_cpu: _job_cpu,
job_name: _job_name
],
reception_action: (
set_timer(_event,600,'ready event')
)
).Refer to Tivoli Enterprise Console® User's Guide and Tivoli Enterprise Console Rule Builder's Guide for details about rules commands.