Monitoring jobs running on multiple engines
This scenario describes how you use the Dynamic Workload Console to create a task to simultaneously monitor jobs that run on multiple engines, which can be in mixed distributed and z/OS environments.
Overview
High efficiency batch processing relies on powerful monitoring capabilities. The need for a single operator to monitor systems is continuously increasing. Up until about 10 years ago, only a limited amount of workload was monitored, but this is increasing to the monitoring of an entire division, and even to an entire company.
Today operators frequently have to monitor multiple large divisions or multiple companies for service providers. These operators work in shifts in multiple geographical locations according to a "follow-the-sun" approach, in some cases. They must try to balance what must be monitored with the size of the monitored environment.
Business scenario
In this scenario, an insurance company, named Starbank, consists of a headquarters where its central office accounting department is located, and multiple branch offices located all over the world, where several administrative departments perform accounting activities.
The central office is in charge of the company's entire accounting workload. Therefore, the HCL Workload Automation operator must verify that all the workload processing for the Starbank company proceeds smoothly and without errors and needs a comprehensive workload management solution.
To achieve this goal, the operator needs to create a task that he can run every day to monitor all the administrative jobs, detecting in real time any possible failures.
However, although the sales department of the company runs its jobs in a z/OS environment, the single business units run their jobs in distributed environments. The operator needs a single console panel, from which he can control all the jobs, both z/OS and distributed, at the same time.
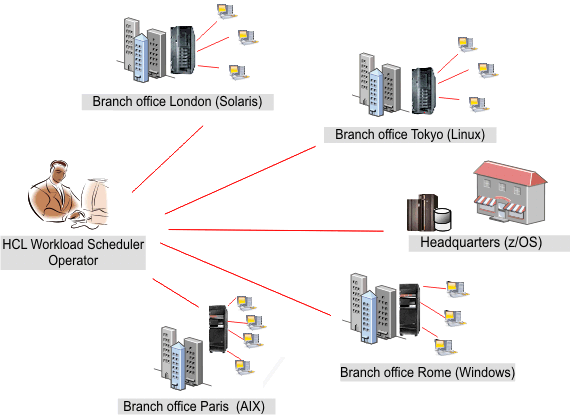
The operator creates a task to monitor jobs that run on multiple engines, including both the environments. He does this by creating and running a task to Monitor Jobs on multiple engines.
Creating a Monitor Jobs task for multiple engines
The operator logs in to the Dynamic Workload Console and, from the navigation bar, he clicks System Status and Health > Workload Monitoring > Monitor Workload .
To create a task using Monitor Workload, see Creating a monitoring task query.
Selecting the engines
In the Enter Task Information panel, the operator specifies a name for the task, for example AccError, and defines the scheduler engines on which to run the task.According to a company naming convention policy, all the engine names have a prefix specifying to which department they belong. Therefore, the operator includes in the Selected Engines list all the engines named acc_*. The operator then organizes the list by importance, placing the engines belonging to the most critical company departments (like Finance and Sales) at the beginning of the list, so as to have their results displayed as the first rows of the table. The task runs following the engine sequence, but the results are displayed altogether, only after the task has run on all the engines in the list.
Defining the filter
In the General Filter panel, the HCL Workload Automation operator specifies some filtering criteria to limit the results retrieved by the query. Here he starts refining the scope of the query by also considering the amount of information to retrieve. Defining a meaningful filter is very important to avoid unnecessary overhead, considering that the task runs on multiple engines. First, the operator sets the automatic refresh time to 600 so as to receive the updated monitoring results every 600 seconds (10 minutes). He then filters for jobs based on their job streams. According to a company policy, all administrative job streams begin with the company name followed by the department code. In our scenario, the operator looks for all the job streams whose identifier starts with Starb* that did not complete successfully.Selecting the columns
In the Columns Definition panel, the operator selects the information to display in the table containing the query results. According to the columns he chooses, the corresponding information is displayed in the task results table. In our scenario, for all the jobs resulting from the query, the operator wants to see their statuses, the job streams they belong to, when they were scheduled to run, and the engines on which they ran. Then, if more details are necessary, he can drill down into this information displayed in the table of results and navigate it.Results
In the All Configured Tasks panel, the operator can see the main details about the task that he has just created and launch the task immediately. The task is now in the list of saved tasks from where the operator can open and modify it any time. To find the task from the displayed task lists, he clicks the following options: System Status and Health > Workload Monitoring > Monitor Workload.
The operator has created a task that can be run every day to highlight possible critical failure in real time. If there is a failure in any of the administrative jobs run by the selected offices, the operator discovers it no later than 10 minutes after the error occurs.
Running the Monitor Jobs task for multiple engines
To launch the task, the operator clicks System Status and Health > Workload Monitoring > Monitor Workload.
The operator clicks AccError task to launch it. Because some engine connections do not work correctly, the Checking engine connections panel reports some errors on two of the eight engines defined. The failing connections are the Tokyo and Paris offices. The operator could ignore the failed connections and proceed, running the task on the successful engines only. However, monitoring the entire workload running in all the branch offices is crucial to his activity, and he does not want to skip any engine connection. Therefore, by clicking Fix it next to each failing engine connection, the operator opens a dialog where he can enter the credentials required for that engine. After entering the correct credentials, also the remaining engine connections work successfully and the operator clicks Proceed to run the task against all the engines.
Viewing results and taking corrective actions
Viewing the results of the AccError task, the operator realizes that there is a job in error, named PayAcc1. He right-clicks the job to open its job log, to better determine the cause and effects of this error.
From the job log, he finds out that only the last step of the job failed, which was a data backup process. This step can be done manually at a later time. The most important part of the job, consisting of the accounting processes related to payrolls, completed successfully.
Now the operator needs to determine the impact that this job in error has on the overall plan. To do this, he selects the PayAcc1 job and clicks Job Stream View. From this view, he realizes that this job is a predecessor dependency of another job, named Balance1. The operator releases the failing job dependency so as to make it possible for the successor Balance1 to start and the whole workload processing to complete.
A second job in error results from the AccError task. It is a z/OS job, named Info. The operator selects this job from the list and right-clicks it to open the Operator Instructions that give him important information about what to do. According to the instructions, this is an optional procedure, which can be skipped without consequence for the entire processing. Therefore, the operator right-clicks the job and cancels it.
The operator then refreshes the view to ensure that there are no other jobs in error.
To
view connection status information and statistical information about
the engines against which the task was run, the operator clicks the
statistical icon  on the table toolbar.
on the table toolbar.
A pie chart showing the number of query results and job status is displayed for each engine on which the task ran successfully. By clicking the pie sections, he can see further details. If the task did not run successfully run on one or more engines, he sees a message containing details about the errors.